기준용어 매핑 최신 근황
현장에서 자주 듣는 이야기가 있습니다. 기준용어(reference data)는 회사마다 방대하고, 실제로는 수기 입력이 많고, 나라마다 표기와 입력 방식이 달라서, 로컬·수기 표현을 표준 용어에 맞추는 자동 매핑이 쉽지 않다는 것입니다. 이 문제는 학술적으로 entity matching(엔티티 매칭) / record linkage / entity resolution 라고 불립니다. 정답이 하나로 정해진 분야는 아니고, 아래는 '요즘 이렇게도 한다'에 가까운 정리입니다. 데이터 규모·언어·정합성 요구에 따라 골라 쓰는 편이 맞습니다.
(아래 내용은 1차 출처를 직접 확인해 정리했지만, 수치·세부는 데이터와 환경에 따라 달라질 수 있으니 참고 수준으로 봐 주세요.)
요즘 쓰는 파이프라인
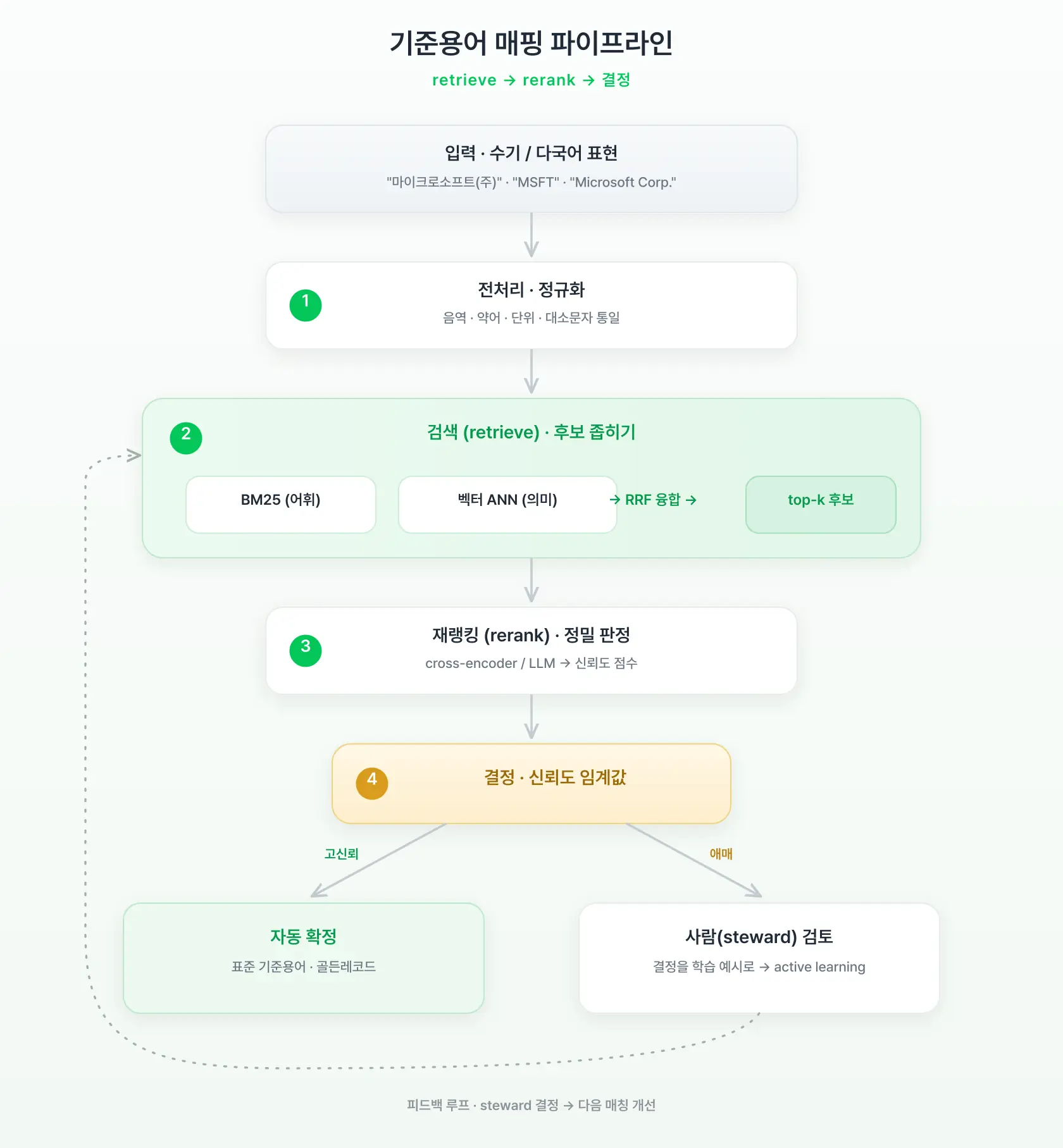
용어 정규화·매핑은 대체로 아래 단계를 따르는 경우가 많습니다. 절대적인 정석은 아니지만, 방대한 표준 카탈로그를 한 번에 비교하지 않고 먼저 후보를 좁힌 뒤 정밀 판정하는 2단계 구조가 흔합니다.
- 전처리·정규화 — 유니코드/음역 통일, 대소문자·단위·약어 정리
- 블로킹(후보 생성) — N×M 비교를 줄임. 요즘은 고전적 blocking key 대신 임베딩 ANN 검색으로 top-k 후보를 뽑음
- 매칭·재랭킹 — retrieve-then-rerank: bi-encoder로 검색 → cross-encoder 또는 LLM으로 정밀 판정
- 결정·골든레코드 — 임계값 + survivorship(생존 규칙)으로 표준값 확정
- 휴먼 검증 — data steward 검토, 신뢰도가 높으면 자동 확정·낮으면 검토 큐로 분기
- 피드백 루프 — steward 결정을 학습 예시로 재활용(active learning)
상용 MDM(master data management) 제품도 이런 구조를 따르는 경우가 많습니다. 예로 Semarchy xDM은 match group 생성 → 골든레코드 병합 → 확정 → survivorship 통합으로 흐르고, 퍼지 매칭과 ID(정확) 매칭을 구분하며, 신뢰도 점수에 따라 자동 병합과 steward 검토로 분기합니다. 출처: Semarchy xDM matching 문서. 비슷한 상용으로 Informatica·Reltio·SAP MDG·Tamr, 오픈소스로 Magellan(py_entitymatching)·Zingg·dedupe·RecordLinkage 등이 있습니다.
검색(retrieval) 알고리즘 — 후보를 좁히는 방법
후보를 좁히는 '검색' 단계에서 쓰는 방법도 한 가지가 아닙니다. 하나만 쓰기보다 섞어 쓰는 경우가 늘었고, 어느 게 정답이라기보다 데이터 성격에 따라 고르는 편입니다.
- BM25(어휘 검색) — 역색인 기반 고전 키워드 매칭. 빠르고 설명 가능하지만 오타·약어·다국어 표현엔 약한 편
- 밀집 벡터 + ANN — 임베딩을 HNSW·IVF 같은 근사 최근접 탐색으로 검색(FAISS, pgvector 등). 표기가 달라도 의미가 가까우면 잡아냄
- 하이브리드(BM25 + 벡터) — 둘을 함께 돌려 RRF(Reciprocal Rank Fusion) 로 융합. 가중치 튜닝 없이 1/(k+순위) 합으로 합치며, 단독보다 나은 경우가 많아 검색엔진들이 기본 옵션으로 제공하는 추세. 출처: Elasticsearch RRF 문서
- 학습형 희소 검색(SPLADE) — 역색인을 그대로 쓰면서 용어 확장을 학습. BM25의 운영 이점과 신경망 성능을 절충하려는 접근. arXiv 2107.05720
- late interaction(ColBERT) — 토큰 단위로 비교(MaxSim)해 정밀도를 높임. 문서 표현을 미리 계산해 둬 비교적 효율적. arXiv 2004.12832
- cross-encoder 리랭커 — 검색으로 좁힌 top-k를 최종 재정렬하는 별도 모델(Cohere Rerank, bge-reranker 류). 정확도는 올라가지만 비용·지연이 늘어 보통 소수 후보에만 적용
실무에서는 BM25 + 벡터 하이브리드로 후보를 뽑고, cross-encoder/LLM으로 재랭킹하는 조합을 흔히 봅니다. 다만 하이브리드가 항상 이기는 건 아니어서, 자체 데이터로 BM25 단독·벡터 단독·하이브리드를 비교해 보는 걸 권합니다.
코드로 보는 한 번의 매핑
말로만 보면 추상적이라, 가짜 예시로 한 사이클을 코드로 따라가 봅니다. 아래 네 토막은 위 다이어그램의 ① 전처리 → ② 검색 → ③ 재랭킹 → ④ 결정 에 그대로 대응합니다. (라이브러리·모델명은 예시이니 환경에 맞게 바꾸면 됩니다.)
import re
def normalize(s: str) -> str:
s = s.lower().strip()
s = s.replace("(주)", "").replace("주식회사", "")
return re.sub(r"\s+", " ", s)
normalize("마이크로소프트(주)") # -> "마이크로소프트"# 1) 두 검색기로 각각 top-k 후보를 뽑는다
bm25_ids = bm25_search(query, k=50) # 어휘(BM25)
vector_ids = vector_search(query, k=50) # 의미(임베딩 ANN)
# 2) RRF로 두 순위를 합친다 (가중치 튜닝 불필요)
def rrf(rankings, k=60):
scores = {}
for ranking in rankings:
for rank, doc_id in enumerate(ranking):
scores[doc_id] = scores.get(doc_id, 0) + 1 / (k + rank)
return sorted(scores, key=scores.get, reverse=True)
candidates = rrf([bm25_ids, vector_ids])[:20]from sentence_transformers import CrossEncoder
reranker = CrossEncoder("BAAI/bge-reranker-v2-m3") # 예시 모델
pairs = [(query, standard_terms[c]) for c in candidates]
scores = reranker.predict(pairs) # 후보별 신뢰도
best, conf = candidates[scores.argmax()], float(scores.max())
if conf >= 0.90:
confirm(best) # 자동 확정 → 골든레코드
else:
send_to_steward(query, candidates[:5]) # 애매하면 사람 검토 큐임계값으로 거르고도 애매한 후보는, 마지막에 LLM에게 판정을 맡기기도 합니다. 자유 생성 대신 후보를 제시하고 그 안에서 고르게 제약하는 게 안전합니다.
[질의] "MSFT"
[후보]
1. Microsoft Corporation
2. MicroStrategy Inc.
3. Microchip Technology
[지시] 질의와 같은 회사인 후보 번호와 신뢰도(0~1)를 JSON으로만 답하라.
[출력] {"match": 1, "confidence": 0.97}LLM·RAG가 바꾼 것
- retrieve-then-rerank — 빠른 임베딩 검색으로 1차 후보, LLM/cross-encoder로 2차 재랭킹. 품질과 비용·지연의 균형점. 출처: LlamaIndex
- LLM few-shot 매칭 — 'Microsoft Corporation'과 'MSFT'처럼 표기가 달라도 동일 엔티티임을 의미적으로 인식. 수작업 피처 엔지니어링 의존을 줄임
- cross-lingual — 다국어 임베딩으로 나라별 언어 차이를 흡수, 글로벌 데이터 통합에 유리
특히 Peeters·Steiner·Bizer, "Entity Matching using LLMs" (arXiv 2310.11244)는 최고 성능 LLM이 학습 예시 없이(또는 소수만으로) 수천 건으로 파인튜닝한 BERT/RoBERTa급 성능을 내고, 미관측 엔티티에 더 강건하다고 보고합니다. 라벨링 비용이 큰 현장에서 의미 있는 결과입니다.
대표 논문·벤치마크
- Ditto — 엔티티 매칭을 시퀀스쌍 분류로 보고 PLM을 파인튜닝. 기존 SOTA 대비 최대 +29% F1, 라벨 절반으로 SOTA 도달(도메인 지식 주입·데이터 증강 포함). arXiv 2004.00584
- Deepmatcher / Magellan — clean 구조화 데이터엔 딥러닝이 전통 기법과 동급이지만 훨씬 느리고, 텍스트·dirty 데이터엔 딥러닝이 우위. 데이터 성격에 따라 선택하라는 교훈. SIGMOD'18
- WDC Products — 코너케이스 난이도·미관측 엔티티 비율·학습량을 조절하는 다차원 벤치마크. 모든 기법이 미관측 엔티티에서 성능이 떨어진다는 점을 정량화. arXiv 2301.09521
- OpenSanctions Pairs — 755,540 라벨 쌍·293 소스·31개국의 대규모 다국어/교차문자 벤치마크. 논문이 평가한 모델 기준 GPT-4o 98.95% F1, 로컬 배포형 오픈모델(DeepSeek-R1-Distill-Qwen-14B) 98.23%가 룰기반 91.33%를 상회. arXiv 2603.11051
- STEPMatch — 짧은 다국어 전자세금계산서 품목명을 blocking + 하이브리드(BM25+SBERT, RRF) 검색 + 다국어 cross-encoder 재랭킹으로 매칭. 영어→포르투갈어 cross-lingual 전이가 타깃 단독 학습을 능가(약 98.6 vs 94.3). SciTePress 2025
- BERTMap — 온톨로지/용어 정렬을 코퍼스 구성 → BERT 파인튜닝 → 매핑 예측 → 정제의 4단계로. 'after-candidate-classify-then-refine' 구조가 용어 정규화와 비슷함. AAAI 2022
수치는 모두 논문이 평가한 시점의 모델 기준입니다. GPT-4o처럼 지금 보면 구형인 모델도 있으니, 실제 도입 시에는 최신 모델(예: Claude Opus 4 계열, GPT-5 계열, Gemini, 최신 오픈 LLM)로 다시 재보는 게 맞습니다 — 성능 여지는 더 있다고 보는 편이 안전합니다.
"방대함 + 다국어 수기입력"에 특히 효과적인 것
- retrieve-then-rerank — 방대한 카탈로그를 임베딩 검색으로 좁히고 정밀 판정. 규모 확장의 핵심
- 다국어 임베딩(LaBSE, multilingual-e5, BGE-M3 등) — 나라별 언어·표기 차이 흡수
- dirty·free-text 수기입력엔 LLM/딥러닝 — Deepmatcher가 보여준 '텍스트·dirty 우위'와 일치
- cross-lingual 전이 — 타깃 언어 라벨이 적을 때 고자원 언어에서 전이(STEPMatch)
- 휴먼 검증 + active learning — 롱테일은 steward가 잡고, 그 결정을 예시로 축적
한계
- 코너케이스(닮은 비매치 / 안 닮은 매치)에서 모든 기법의 성능이 급락
- 미관측 엔티티 일반화가 약함 — 학습에 없던 새 엔티티에서 정확도 하락
- 교차문자 음역·식별자 off-by-one 은 LLM의 대표적 실패 모드(아랍/키릴/라틴)
- LLM 비용·지연·환각 — 자유 생성 대신 RAG로 후보를 제약해야 안전
- clean·ID 보유 데이터 엔 LLM/딥러닝이 비용 대비 비효율(전통 매처로 충분)
실무에서 자주 보이는 선택
정해진 정석이라기보다, 비슷한 문제에서 자주 선택되는 형태입니다. 환경에 따라 일부만 취해도 됩니다.
- 표준 기준용어를 다국어 임베딩 벡터 인덱스로 구축
- BM25+벡터 하이브리드(RRF) 검색 → LLM/cross-encoder 재랭킹 + 신뢰도 점수
- 2단계 임계값: 고신뢰는 자동 확정, 애매한 건 steward 큐
- 데이터 분기: dirty·다국어 free-text→최신 LLM(Claude Opus 4 계열·GPT-5 계열 등), clean·ID 보유→exact/rule (비용 절감)
- steward 결정으로 few-shot 예시·active learning 축적
- 평가셋에 코너케이스·미관측 엔티티 를 포함해 현실 난이도 반영
정리하면, 기준용어 매핑은 룰·사전 매칭만의 문제라기보다 검색(retrieval)과 LLM 판정을 결합한 파이프라인 설계 문제에 가까워지는 흐름입니다. 다만 환경마다 답이 다르니, 위 논문·문서를 출발점 삼아 자체 데이터로 직접 비교해 보시길 권합니다.